

实验室春游之旅!在这个温暖的季节,我们一同来到了呼和浩特大青山。和煦的阳光洒在大地上,我们放飞自由的风筝,让它们在蓝天白云间舞动。欢声笑语中,我们一同坐下来,摆出棋牌,展开激烈而有趣的对决,智慧与竞技在棋盘上交织。
而临近黄昏,诱人的烤肉香气飘散开来,我们一起烤制美味的烧烤,品尝烤肉的香嫩口感,享受着友谊与美食的双重滋味。大家围坐在篝火旁,品味美食的同时,我们畅所欲言,讨论着实验室的未来,分享着彼此的思考和见解。
这次春游,不仅是一段欢乐的时光,更是我们实验室成员之间紧密联系的机会。通过放风筝、打棋牌、吃烧烤,我们不仅欢乐共度,更激发了智慧和创造力的火花。相信这次活动将为我们带来更多的灵感和团结,让我们在未来的科研道路上一同前行,创造更加辉煌的成就!
让我们怀着美好回忆,满怀期待地迎接下一个实验室的精彩活动吧!









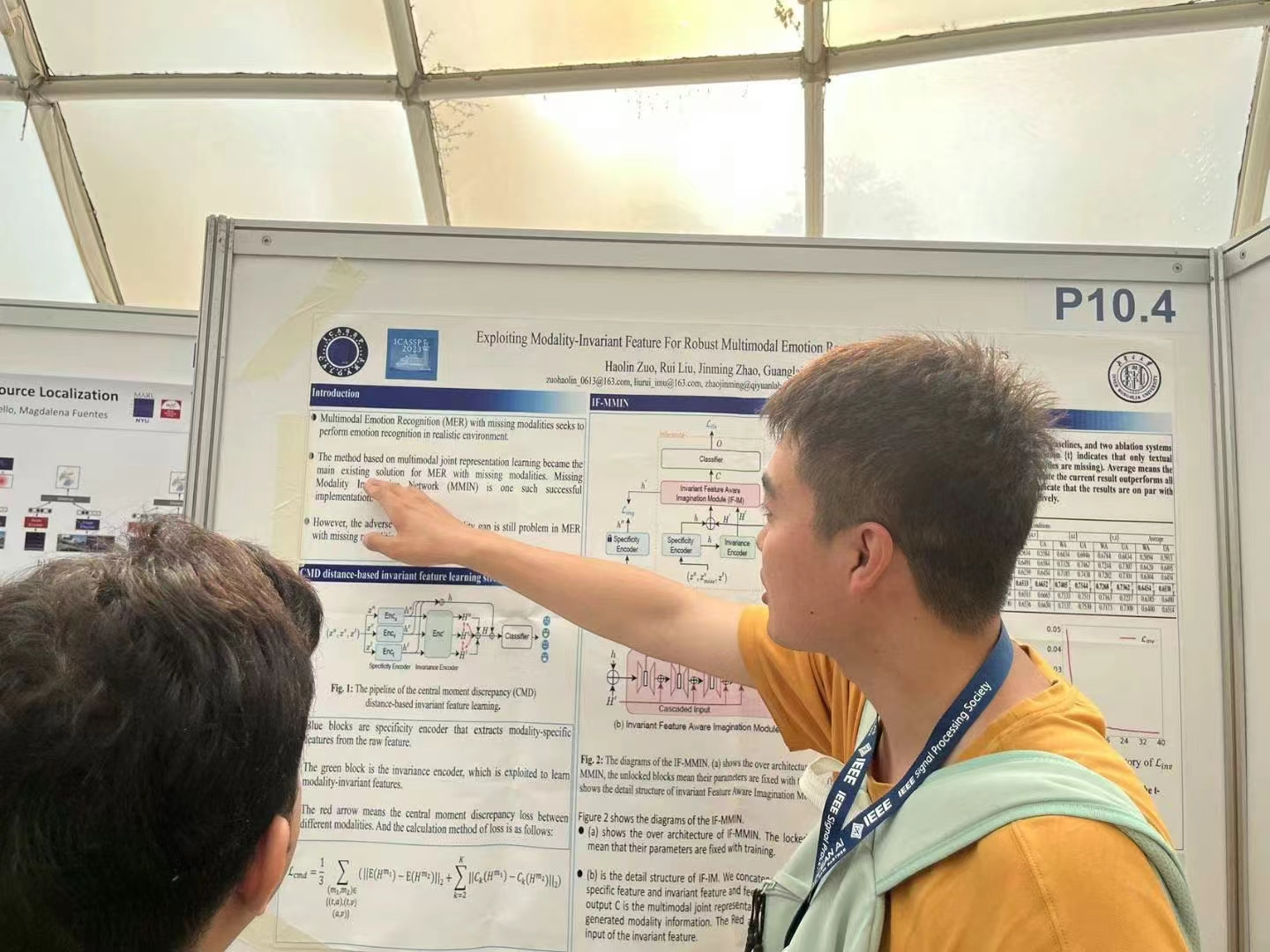
ICASSP 2023 国际会议于 2023 年 6 月 4 日至 10 日在希腊罗德岛举行。这是 第 48 届 IEEE 声学、语音和信号处理国际会议的。会议将在罗多斯宫豪华会议度假村举行,刘瑞研究员与23级博士生左昊麟参会并汇报了工作。
今年的 ICASSP 主题是“人工智能时代的信号处理”,旨在推动信号处理与机器学习之间的创造性协同。会议的参与人数破纪录地增长,其中现场参会人数超过 3700 人,这反映了信号处理在现代学术界和工业界的核心作用。
在本次 ICASSP 中,左昊麟汇报了工作:《Exploiting Modality-invariant Feature For Robust Multimodal Eemotion Recognition With Missing Modalities》。
Abstract: Multimodal emotion recognition leverages complementary information across modalities to gain performance. However, we cannot guarantee that the data of all modalities are always present in practice. In the studies to predict the missing data across modalities, the inherent difference between heterogeneous modalities, namely the modality gap, presents a challenge. To address this, we propose to use invariant features for a missing modality imagination network (IF-MMIN) which includes two novel mechanisms: 1) an invariant feature learning strategy that is based on the central moment discrepancy (CMD) distance under the full-modality scenario; 2) an invariant feature based imagination module (IF-IM) to alleviate the modality gap during the missing modalities prediction, thus improving the robustness of multimodal joint representation. Comprehensive experiments on the benchmark dataset IEMOCAP demonstrate that the proposed model outperforms all baselines and invariantly improves the overall emotion recognition performance under uncertain missing-modality conditions.
参会人员合照:

InterSpeech 2023 是世界上最大、最全面的语音处理科学技术会议,于 2023年 8 月 20 日至 24 日在爱尔兰都柏林会议中心举行。这次会议为语音处理领域的专家学者提供了一个重要的交流平台。
在会议上,刘瑞研究员汇报工作:《Explicit Intensity Control for Accented Text-to-speech》。
Abstract: Accented text-to-speech (TTS) synthesis seeks to generate speech with an accent (L2) as a variant of the standard version (L1). How to control the intensity of accent is a very interesting research direction. Recent works design a speaker-adversarial loss to disentangle the speaker and accent information, and then adjust the loss weight to control the accent intensity. However,there is no direct correlation between the disentanglement factor and natural accent intensity. To this end, this paper proposes a new intuitive and explicit accent intensity control scheme for accented TTS. Specifically, we first extract the posterior probability from the L1 speech recognition model to quantify the phoneme accent intensity for accented speech, then design a FastSpeech2 based TTS model, named Ai-TTS, to take the accent intensity expression into account during speech generation. Experiments show that our method outperformsthe baseline model in terms of accent rendering and intensity control.

22级硕士生张锦华汇报工作:《Betray Oneself: A Novel Audio DeepFake Detection Model via Mono-to-Stereo Conversion》。
Abstract: Audio Deepfake Detection (ADD) aims to detect the fake audio generated by text-to-speech (TTS), voice conversion (VC) and replay, etc., which is an emerging topic. Traditionally we take the mono signal as input and focus on robust feature extraction and effective classifier design. However, the dual-channel stereo information in the audio signal also includes important cues for deepfake, which has not been studied in the prior work. In this paper, we propose a novel ADD model, termed as M2S-ADD, that attempts to discover audio authenticity cues during the mono-to-stereo conversion process. We first projects the mono to a stereo signal using a pretrained stereo synthesizer, then employs a dual-branch neural architecture to process the left and right channel signals, respectively. In this way, we effectively reveal the artifacts in the fake audio, thus improve the ADD performance. The experiments on the ASVspoof2019 database show that M2S-ADD outperforms all baselines that input mono. We release the source code at https://github.com/AI-S2-Lab/M2S-ADD.

在 InterSpeech 2023,白天充满了高质量的研究和充满活力的讨论,夜晚则充满了文化、创造力和乐趣。S2LAB团队成员与来自世界各地的学者建立联系的机会是无与伦比的。这次会议的成功归功于所有参与者的努力和热情,他们共同营造了一个包容性、多样性代表并重的交流环境。 InterSpeech 2023 为语音处理领域的进步和创新注入了新的活力和动力,我们期待着在未来的会议中与各方学者再次相会InterSpeech。


2023年第十八届全国人机语音通讯学术会议(National Conference on Man-Machine Speech Communication,NCMMSC2023)于2023年12月8至10日在江苏苏州CCF业务总部&学术交流中心圆满举行!该系列会议自1990年开创以来已成功召开了十七届,是国内语音领域广大专家、学者和科研工作者交流最新研究成果,促进该领域研究和开发工作不断进步的重要舞台!
大会邀请上海交通大学副校长朱新远、清华大学马少平教授、北京工业大学鲍长春教授等多位领导做开幕式致辞,上海交通大学俞凯教授对大会举办情况进行介绍。大会同时邀请清华大学唐杰教授、香港中文大学Helen Meng教授、香港中文大学(深圳)李海洲教授带来了各自领域的精彩专题报告。本次大会通过大会报告、口头报告、墙报和演示的方式为参会者提供语音语言领域最新理论和实际工程技术的交流平台,同时举办了多模态识别竞赛、ASRU交流会、优秀学生论坛、工业论坛、专题技术沙龙等多场活动。本次会议共包含口头报告53个,墙报112篇,工业论坛7场、优秀学生论坛24场。大会充分展现了NCMMSC会议所秉承的学术交流互鉴理念,不断推动和支持国内语音领域青年学者的成长和交流。
会议期间,与会专家学者围绕人机语音通讯技术的发展趋势、关键技术、应用场景等方面展开了深入的交流与讨论。多位知名专家分别就语音识别、语音合成、情感计算、多模态交互等热点问题发表了主题报告,展示了人机语音通讯技术的最新进展!本次会议多元化的内容全面展示了会议所倡导的学术交流互鉴理念,并积极促进和支持国内语音领域年轻学者的成长和交流!
张锦华同学在大会汇报论文《基于深度学习的蒙古语合成语音检测研究》
论文摘要:合成语音检测是用于识别和鉴别计算机生成的合成语音与真实人类语音之间的差异,以侦测可能的虚假信息或欺骗。这种技术通常用于声纹识别和反欺诈应用中,以提高安全性和身份验证的可靠性。近年来,针对英语、汉语等主流语言的合成语音检测工作发展迅速,但是针对蒙古语等小语种的合成语音检测工作还处于空白阶段。鉴于蒙古语语音合成近几年的发展成果,为了填补这一空白,我们基于实验室强大的蒙古语语音合成模型构建了蒙古语合成语音检测数据集,并在该数据集上对主流的合成语音检测框架进行试验比较,同时我们在https://github. com/ssmlkl/NCMMSC2023开源了相关数据集和基线模型。本文是首次对蒙古语合成语音检测展开深入研究,旨在推动蒙古语的合成语音检测领域的发展,为小语种合成语音检测的研究做出一定贡献。

刘瑞老师作为大会工业联络主席,主持了9号下午的工业论坛会议。会议上,熊世富(科大讯飞)对于大模型语音应用如何落地进行了深入浅出的讲解、郝玉峰 (海天瑞声)对大模型时代的语音技术发展里程进行了深刻剖析、周彤 (标贝科技)介绍了基于数据大模型的数据标注平台。

本次全国人机语音通讯学术会议的成功举办,为人机语音通讯技术的发展搭建了一个良好的交流平台,有力地推动了相关领域的技术创新和产业发展。未来,随着人工智能技术的不断进步,人机语音通讯技术将在更多领域发挥重要作用,为人们的生活带来更多便捷和惊喜!大会期间,实验室团队还与参会的专家学者进行了多方位的学术交流,收获颇丰。下一届NCMMSC将在新疆大学举办,期待与同行的再次相会。

中国中文信息学会(CIPS)计算语言学专委会2024年战略研讨会于6月1日至2日在内蒙古呼和浩特顺利召开。此次研讨会由CIPS计算语言学专委会(简称专委会)主办,内蒙古大学和蒙古文智能信息处理技术国家地方联合工程研究中心承办。研讨会的主题是“大模型的能与不能”。来自全国各地的专委40余位专委会委员参加了本次研讨会,通过特邀报告和论坛研讨的方式,深度探讨了大模型背景下自然语言处理研究所面临的挑战与机遇。
研讨会于6月1日上午8点50分正式开幕。开幕式由专委会副主任、哈尔滨工业大学车万翔教授主持。蒙古文智能信息处理技术国家地方联合工程研究中心主任高光来教授致欢迎辞,对专委们的到来表示了诚挚的欢迎,介绍了内蒙古大学和蒙古文智能信息处理技术国家地方联合工程研究中心的基本情况,鼓励大家抓紧机遇,打好人工智能时代的“大模型底座”,并预祝研讨会圆满成功。专委会主任、清华大学刘洋教授代表专委会对承办单位的办会工作表示由衷感谢,并热烈欢迎与会专委。同时,刘洋教授简要介绍了研讨会设立的目的和专委会的年度工作重点,并对专委会未来发展提出期望。


本次研讨会设三组共十一个特邀报告,分别涉及大模型语言能力和大模型任务能力两方面。第一阶段特邀报告由专委会副主任、哈尔滨工业大学车万翔教授和中国科学院自动化研究所刘康研究员主持。北京语言大学荀恩东教授作了题为《大模型下高质量高价值数据》的报告,从计算语言学的内涵演变、NLP研究范式、NLP算法、NLP数据、数据规模增长、类人神经结构、类人认知过程、自然语言处理、知识视角等角度分析了大模型带来的变化,并探讨了高质量高价值数据的层次划分,以及语义和语用角度的概念内涵发展。

大连理工大学黄德根教授作了题为《以中文为核心的超大规模机器翻译研究进展》的报告,对大规模机器翻译面临的模型持续学习问题、篇章非自回归解码问题、以及大模型翻译结果的幻觉和偏向性问题进行了讨论,重点报告团队解决上述问题的多种有效方法,并对不同路线的大语言模型机器翻译特点进行了分析,指出了大模型机器翻译未来的研究方向。

西湖大学张岳教授作了题为《模型生成内容的自动检测研究》的报告,指出人类在辨识AI生成内容上的不足,强调进行模型生成内容检测在构建可信交互、避免AI技术误用方面的必要性,探讨了目前自动检测方法的泛化性方面的不足,并重点报告了团队针对有监督检测和零样本检测的相关解决方案。

天津大学熊德意教授作了题为《基于评测的大模型安全治理》的报告,探讨了大模型在语言、知识、推理/工具、AGI/ASI四个方面的能力发展,指出了大模型安全治理方面的挑战,包括对齐、评测和监管,详细介绍了团队在大模型评测开展的系统性工作,包括评测体系、评测标准、评测基准、评测平台和评测大赛,为安全可信大模型构建指明了方向。

南京大学黄书剑副教授作了题为《大语言模型的多语言能力迁移研究》的报告,指出大语言模型存在数据不平衡问题,即预训练数据以英语为主、非英语数据占比很少,总结团队采用扩展中文词表、中文继续预训练、中文指令微调提升中文大模型的方法,以及通过模型扩展、目标语言预训练、翻译预训练、能力恢复和迁移的多阶段框架实现高效跨语言能力迁移的相关研究成果。

大会第二阶段特邀报告由西湖大学张岳教授和复旦大学桂韬副研究员主持。北京大学詹卫东教授作了题为《基于空间布局图式的推理题自动生成研究》的报告,指出合成数据具有可扩展、可控制、降低标注成本、增强数据丰富性等诸多优点,重点介绍了结合常识知识和模版构建空间关系知识库的方法,探讨了目前视觉模型在空间生成任务上的不足。

专委会副主任、哈尔滨工业大学车万翔教授作了题为《从语言大模型到代码大模型》的报告,从自然语言到编程语言和从编程语言到自然语言两个角度探讨了自然语言模型掌握编程语言的意义,从预训练、对齐、应用、高阶应用四个层面总结了代码大模型的相关研究进展情况,用详实具体的案例展示了代码大模型的重要应用,并指出了代码大模型未来研究方向。

中国科学院自动化研究所刘康研究员作了题为《大语言模型中的知识探索》的报告,指出大语言模型作为知识库存在知识的事实性、知识激活的鲁棒性、逻辑推理和数值运算、知识更新难等多个问题,报告了团队在大模型知识分析和知识归纳方面的探索性工作和重要发现。报告指出大语言模型可以实现高阶抽象知识的归纳,通过小模型自我演绎产生数据能够提升模型的归纳性能。报告认为探索大模型中知识机制、内外知识协同、知识更新方法及推理方法,是大模型可信、可用的重要问题。

复旦大学张奇教授作了题为《如何提升大模型任务能力》的报告,指出大模型所有的能力都需要精心设计,很多任务的能力在一开始并不具备,而是不断叠加上去的。报告总结了大模型预训练重要经验和结论,探讨了大语言模型训练中多个关键问题,如数学推理、编程和一般能力与SFT数据量的关系如何、导致性能冲突的关键因素是什么、不同SFT策略对复合数据的影响是什么等问题。报告还给出了知识回答和其他任务冲突出现时的解决方案,为大模型训练提供了有价值的参考。
中国科学院计算技术研究所冯洋研究员作了题为《大模型增强方法研究》的报告,总结了团队在提升大语言模型在机器翻译任务上表现的多个技术优化方案,包括采用交互式翻译增强模型多语言能力,提升语言生成和与人类对齐能力,通过在真实空间编辑大语言模型的内部表示缓解模型幻觉,设计流式注意力机制和源端、目标端独立位置编码的Decoder-only大模型对流式输入进行实时翻译,结合大语言模型和智能体进行流式翻译,对增强大语言模型在翻译任务上的性能具有很好启示意义。

清华大学李鹏副研究员作了题为《开放域大模型智能体》的报告,分析了大模型智能体系统现状,认为当前智能体仍处于发展的初级阶段,距离开放域理想系统仍然具有很大差距。报告指出现有方法框架未遵循智能体-人类-环境统一对齐准则,未完全反映开放域任务特点,难以完全胜任开放域的挑战。报告汇报了团队提出的基于代价约束的工具学习方案、偏好引导的知识传输方案,利用点阵+坐标促进图文协同的主动感知方案,并进一步对统一对齐的未来方向进行了展望。

专委会主任、清华大学刘洋教授主持了论坛研讨环节。与会专委们就过去一年大模型的进展、大模型的能、大模型的不能、以及大模型未来的发展展开了讨论。大家普遍认为大模型还存在着诸多挑战和机遇,很多问题需要进一步深入探究,学术界和工业界应共同努力,把握机遇,应对挑战,推动计算语言学和大模型技术持续发展。
本次研讨会的召开为国内计算语言学领域的学者们提供了一个充分交流研讨的平台,与会的专委们积极分享了最新的研究成果,深入探讨了当前技术的局限性和面临的挑战,展望了行业的未来发展趋势。这些富有洞见的讨论不仅为与会者提供了启发,也为计算语言学在大模型时代的进一步发展注入了新的动力。这次研讨会的成功举办有助于促进国内计算语言学领域的技术创新,加强计算语言学与相关领域的交流与合作,推动大语言模型的应用和实际问题的解决。


2024年8月4日至6日,第28届亚洲语言处理国际会议(IALP 2024)在呼和浩特市隆重举行。会议由中文与东方语言处理学会(COLIPS)主办,内蒙古大学计算机学院(蒙古文智能信息处理技术国家地方联合工程研究中心)承办。
本次会议吸引了来自全亚洲语言处理领域的专家、学者和研究人员参与。与会者包括来自复旦大学、哈尔滨工程大学、暨南大学、上海外国语大学、北京语言大学、西北师范大学、内蒙古大学、内蒙古科技大学、内蒙古工业大学、新加坡南洋理工大学等近40所高校和科研机构的80余名代表,他们以线上线下结合的方式参会,共同探讨了自然语言处理、语音处理、语言学、语言教育、大语言模型等多个领域的前沿课题。大会论文集最终由IEEE出版。
本次大会由香港中文大学(深圳)数据科学学院院长李海洲教授和内蒙古大学前副校长高光来教授共同担任大会主席,并在开幕式上致辞。刘瑞研究员作为程序主席汇报本次大会全部内容。开幕式氛围热烈且富有启发性,为会议的顺利进行奠定了坚实的基础。此外,本次会议还荣幸地邀请到了新加坡南洋理工大学的Eng Siong Chng教授和复旦大学的邱锡鹏教授出席会议并进行专题报告。

李海洲教授进行大会致辞。

高光来教授进行大会致辞。

刘瑞研究员汇报大会日程与内容。

Eng Siong Chng教授的专题报告汇报 了《Enabling LLM for ASR》。

邱锡鹏教授的专题报告汇报 了《From Large Language Model to World Model》。

组委会合照。


2024年8月15日至18日,第十九届全国人机语音通讯学术会议(National Conference on Man-Machine Speech Communication,NCMMSC 2024)暨CCF语音对话与听觉专委会2024年学术会议在新疆乌鲁木齐明园新时代大酒店成功召开!自1990年首次举办以来,该会议已成为语音技术领域内专家、学者及科研精英的盛会,在推动该领域的研究与发展方面发挥了关键作用。大会开幕式上,北京语言大学张劲松教授和上海交通大学俞凯教授致辞,新疆大学艾斯卡尔·艾木都拉教授对大会的举办情况进行了介绍。大会还邀请了新疆大学吾守尔·斯拉木院士、清华大学陶建华教授、北京大学孔江平教授和清华大学张超教授带来精彩的大会报告。
本次大会通过大会报告、口头报告、墙报展示和技术演示等多种形式,为参会者提供了交流语音语言领域最新理论和实际工程技术的平台。会议共包含49篇论文的口头报告、104篇论文的墙报展示,还举办了两场青年论坛(共7次报告)、两场优秀学生论坛(共17次报告)、三场工业论坛(共9次报告)以及六场特殊议题讨论(共19次报告)。此外,还有多项产品和技术展示活动。此次会议有效促进了行业内的知识共享,为技术创新与突破搭建了坚实的桥梁。
会议期间,来自学术界的专家、产业界的工程师和青年学者围绕语音科学、语音技术、音频处理、对话与口语等主题展开了深入的交流与讨论。大会充分体现了促进学术交流的精神,为国内语音领域的青年学者提供了成长与互动的平台,激发了创新思维,共同推动了该领域的蓬勃发展。
刘瑞老师在青年老师论坛作了《面向自然人机对话的语音合成技术》的报告。
报告内容:近几年,基于深度学习技术的语音合成方法取得显著进步,在自然度、表现力和拟人化方面取得显著进展。然而,随着大语言模型技术尤其是GPT-4o等模型的迅猛发展,面向自然人机对话的语音合成技术逐渐受到越来越多学者的关注。该报告围绕对话场景语音合成技术面临的难点与挑战,介绍基于深度学习技术尤其是大语言模型技术在对话语音合成场景中的前沿进展,以及最新研究成果。

赵源同学在大会汇报论文《MCDubber: Multimodal Context-Aware Expressive Video Dubbing》
论文摘要:自动视频配音 (AVD) 旨在根据给定的脚本生成与唇部运动和韵律表达相匹配的语音。目前的 AVD 模型主要利用当前句子的视觉信息来增强合成语音的韵律。然而,考虑生成的配音韵律是否与多模态上下文一致是至关重要的,因为最终视频中配音将与原始上下文相结合。这一点在之前的研究中被忽视了。为了解决这个问题,我们提出了一种多模态上下文感知的视频配音模型,称为 MCDubber,将建模对象从单一句子转变为包含上下文信息的更长序列,以确保全局上下文韵律的一致性。MCDubber 包括三个主要组件:(1)上下文时长对齐器,旨在学习文本与唇部帧之间的上下文感知对齐;(2)上下文韵律预测器,旨在读取全局上下文的视觉序列,并预测上下文感知的全局能量和音高;(3)上下文声学解码器,最终在相邻的目标句子真实 mel 频谱图的帮助下,预测全局上下文 mel 频谱图。通过这一过程,MCDubber 充分考虑了多模态上下文对当前句子配音韵律表达的影响。从输出的上下文 mel 频谱图中提取属于目标句子的 mel 频谱图就是最终所需的配音音频。在 Chem 基准数据集上进行的大量实验表明,我们的 MCDubber 在配音表达性方面显著优于所有先进的基线模型。代码和演示可以在 https://github.com/XiaoYuanJun-zy/MCDubber 获取。

左昊麟同学在在优秀学生论坛活动中做学术报告《Contrastive Learning based Modality-Invariant Feature Acquisition for Robust Multimodal Emotion Recognition with Missing Modalities》
摘要:多模态情感识别(MER)旨在通过探索不同模态之间的互补信息来理解人类表达情感的方式。然而,在现实场景中,难以保证始终获得全模态的数据。为了应对模态缺失的问题,研究人员将重点放在跨模态缺失想象过程中的有意义的联合多模态表示学习上。然而,由于“模态差距”问题,跨模态想象机制容易产生错误,进而影响想象的准确性,并最终影响识别性能。为此,我们在缺失模态想象网络中引入了模态不变特征的概念,该网络包含两个关键模块:1)一个新颖的基于对比学习的模块,用于在全模态下提取模态不变特征;2)一个基于想象的不变特征的鲁棒想象模块,用于在模态缺失情况下重建缺失的信息。最后,我们结合想象出的模态和可用模态进行情感识别。基准数据集的实验结果表明,我们提出的方法优于现有的最先进策略。与我们之前的工作相比,扩展版本在处理缺失模态的多模态情感识别方面更为有效。代码已发布在:https://github.com/ZhuoYulang/CIF-MMIN。

胡一帆同学在优秀学生论坛活动中做学术报告《Emotion Rendering for Conversational Speech Synthesis with Heterogeneous Graph-Based Context Modeling》
摘要:会话语音合成 (CSS) 旨在在对话环境中,通过合适的韵律和情感表达,准确呈现语句的意思。尽管 CSS 任务的重要性已被广泛认可,但由于缺乏情感对话数据集以及状态化情感建模的难度,之前的研究并未深入探讨情感表现的问题。在本文中,我们提出了一种新型的情感 CSS 模型,称为 ECSS,该模型包含两个主要组件:1)为增强情感理解,我们引入了一种基于异构图的情感上下文建模机制,该机制以多源对话历史为输入,建模对话上下文,并从上下文中学习情感线索;2)为实现情感渲染,我们采用了一种基于对比学习的情感渲染模块,以推断目标语句的准确情感风格。为了解决数据稀缺的问题,我们精心创建了类别和强度方面的情感标签,并在现有的对话数据集(DailyTalk)上添加了额外的情感信息标注。客观和主观评估均表明,我们的模型在理解和渲染情感方面优于基线模型。这些评估还强调了全面情感标注的重要性。代码和音频示例可以在以下网址找到:https://github.com/walker-hyf/ECSS。

本次全国人机语音通讯学术会议的圆满召开,为人机语音通讯技术的发展提供了一个卓越的交流平台,积极推动了相关领域的技术创新和产业进步,促进我国语音技术的不断创新和发展。展望未来,随着人工智能技术的不断提升,人机语音通讯技术将在更多领域展现其重要作用,带来更加便利和令人惊喜的生活体验!会议期间,实验室团队与参会专家学者进行了深入的学术交流,收获颇丰。我们期待着在下一届的NCMMSC中与各方学者的再次相会!

2023年7月3日,S2Lab实验室在内蒙古大学计算机学院成功举办了语音语言技术分享会,汇集了国内外顶尖技术专家。邀请了新加坡Tiktok语音算法研究员(任意)与中国科学院自动化研究所多模态人工智能系统全国重点实验室助理研究员(连政),探讨了生成式模型在语音合成和虚拟人生成中的前沿应用,以及多模态情感识别技术的未来方向。本次活动为学术交流和合作提供了宝贵机会,会议详情如下:





内蒙古大学,呼和浩特 — 2023年9月22日,内蒙古大学计算机学院迎来了一场技术盛宴,第二期语音语言技术分享会成功举办。本次分享会邀请了来自微软的资深科学家王培栋,主持人为内蒙古大学计算机学院的博士生导师刘瑞。分享会聚焦于语音识别和翻译领域的最新研究成果,特别介绍了王培栋博士的最新作品:"LAMASSU: A Streaming Language-Agnostic Multilingual Speech Recognition and Translation Model Using Neural Transducers"。分享会的成功举办不仅为在场的学生和研究人员提供了深入的学术交流平台,还加深了对语音语言技术领域的理解和认识。参与者们纷纷表示,他们对LAMASSU的研究成果充满期待,期待它能在未来的语音技术应用中发挥重要作用。这次分享会的举办标志着S2Lab实验室与内蒙古大学计算机学院在语音语言技术领域的积极发展和创新,为学术界和产业界的合作提供了新的机会。未来,我们可以期待更多的技术突破和学术盛事的发生。会议详情如下:





内蒙古大学计算机学院于今日成功举办了一场引人瞩目的研讨会,探讨了语音合成技术的最新进展和前沿技术。这次研讨会旨在将语音合成的领域外数据应用到音色复刻中,引发了与会者的广泛兴趣。 在报告中,浙江大学计算机系博士研究生江子越(师从赵洲教授)深入探讨了语音合成模型在少量领域外数据情况下的音色复刻技术。报告详细介绍了诸如parameter-efficient tuning、speaker encoding等技术,并探讨了它们的原理、优势和局限性。此外,还深入研究了zero-shot音色复刻领域中最先进的算法,如VALL-E、Make-a-voice、MegaTTS、UniAudio等模型,强调了它们对音色复刻的影响和挑战。未来研究方向和语音合成技术的发展也成为了讨论的热点,同时探讨了如何规范语音大模型的使用。 研讨会的亮点之一是来自浙江大学计算机系博士研究生的报告人,他们将zero-shot音色复刻技术的应用演示在字节跳动中,为这一技术的实际应用提供了有力支持。 内蒙古大学计算机学院的这次研讨会汇聚了国内外语音合成领域的专家和研究人员,为语音合成技术的未来发展提供了宝贵的交流和合作机会。这一领域的不断创新和探索将进一步推动语音合成技术向更高水平发展,为各行各业提供更多创新的应用和可能性。





内蒙古大学计算机学院近日举办了一场技术分享会,邀请新加坡南洋理工大学的Eng Siong Chng教授进行专题讲座。Prof. Chng深入探讨了如何将语音模态整合到解码器仅接受文本输入的语言模型(LLM)中,并展示了这一领域的最新研究进展。Prof. Chng首先介绍了语言模型的演变过程,特别是最初仅处理文本输入的LLM(如ChatGPT)。随着技术的发展,LLM如今已能够处理包括音频、视频和图像在内的多种模态。他阐述了研究社区在整合语音模态方面提出的多种创新方法,其中包括离散表示的应用、将预训练的编码器与现有的LLM解码器架构(如Qwen)相结合、多任务学习以及多模态预训练。在分享会上,Prof. Chng重点介绍了NTU语音实验室的两项重要研究成果。第一项是“Hyporadise”项目,该项目通过利用LLM处理传统语音识别模型生成的N-best假设列表,从而提高最佳转录结果的准确性。研究表明,LLM不仅在传统语言模型的重排序任务中表现出色,还具备生成N-best假设中未包含的正确词语的能力,这一创新能力被称为生成式错误纠正(GER)。第二项研究探讨了如何在噪声环境下应用LLM进行语音识别。通过扩展Hyporadise方法,研究团队引入了噪声语言嵌入技术,捕捉了低信噪比(SNR)条件下N-best假设的多样性,并通过微调模型显著提升了GER性能。这一成果展示了LLM在处理复杂语音识别任务中的潜力,特别是在具有挑战性的噪声环境中。此次分享会为与会者提供了宝贵的学术交流机会,让大家更深入地了解了LLM在语音识别中的应用前景。Prof. Chng的讲座内容丰富、前沿,为语音处理领域的研究注入了新的活力。

